Les clients parlent aux serveurs
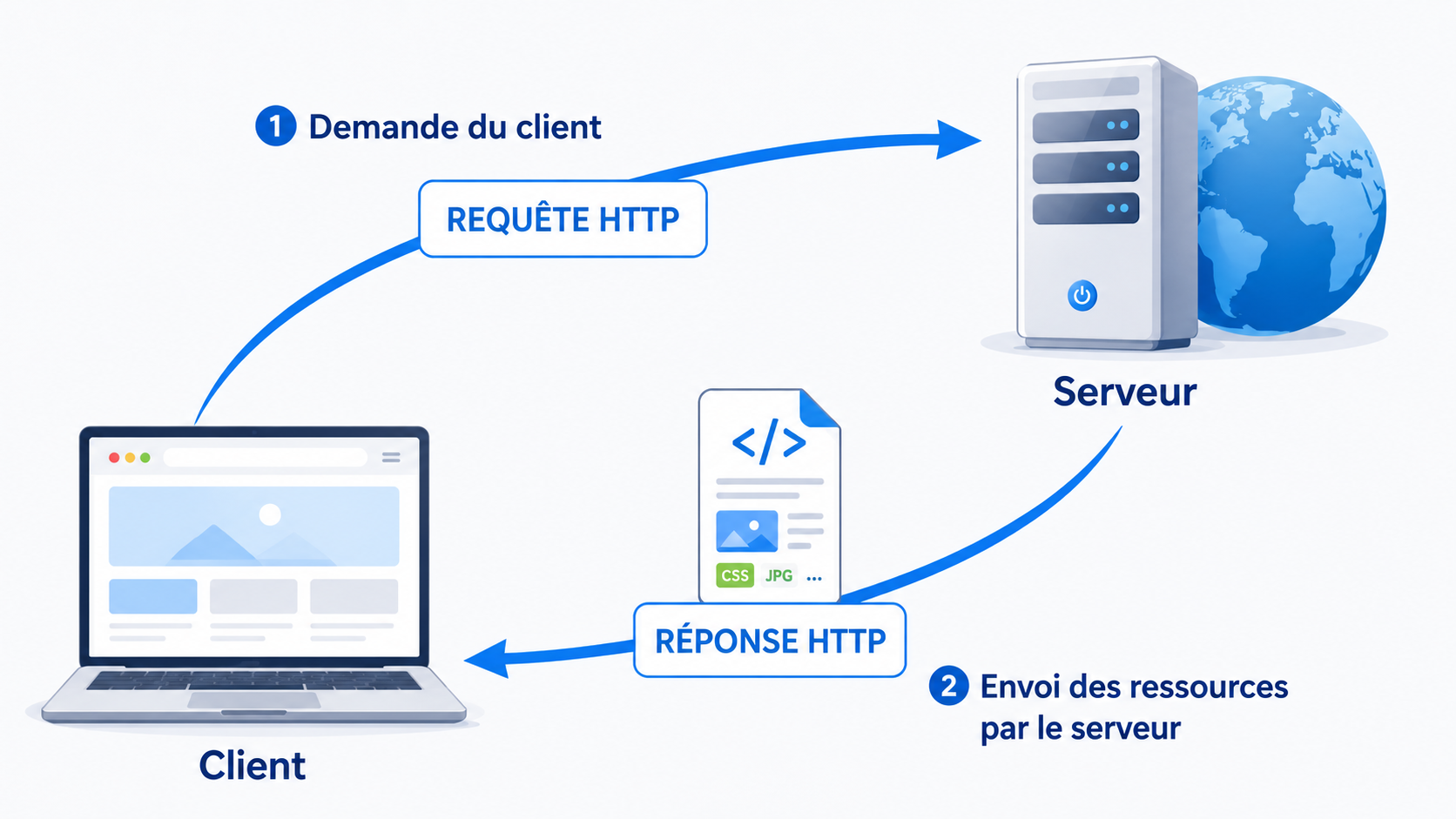
Les ressources du Web (pages HTML, images, vidéos, fichiers audio…) sont stockées sur des ordinateurs spécialisés appelés serveurs. Elles peuvent être consultées par n'importe quel ordinateur connecté à Internet, grâce à une application appelée client — le plus souvent un navigateur web.
Pour communiquer, clients et serveurs utilisent un protocole commun : le protocole HTTP (HyperText Transfer Protocol). Cette communication fonctionne en deux temps :
- Le navigateur envoie une demande au serveur : c'est la requête HTTP.
- Le serveur renvoie les ressources demandées : c'est la réponse HTTP.
Les mots « client » et « serveur » désignent à la fois les logiciels qui assurent chaque rôle, et, par extension, les ordinateurs sur lesquels ils sont installés.
Affichage d'une page web et requêtes HTTP

Lorsqu'un utilisateur saisit une URL dans son navigateur, plusieurs requêtes HTTP sont nécessaires pour afficher la page. Prenons l'exemple d'une page HTML contenant une seule image JPEG :
- Le navigateur envoie une requête pour récupérer le fichier HTML de la page.
- En lisant ce fichier HTML, le navigateur détecte qu'il a besoin d'un fichier CSS : il effectue une deuxième requête.
- Le navigateur détecte aussi l'image JPEG : il effectue une troisième requête pour la récupérer.
Une fois les trois fichiers reçus, le navigateur peut enfin afficher la page complète. C'est le principe de l'hypertexte : le fichier HTML de départ contient des liens vers toutes les ressources nécessaires.